Open-Source Text-to-SQL in Python Using AI (LLMs)
We’re excited to announce a significant milestone: Vanna is now available as an open-source package. This move is an essential step in our journey to democratize access to AI-powered SQL generation. Today, we'll discuss the challenges Vanna helps solve, why we're going open source, how to deploy Vanna locally, and so much more.
We already had our Python package open sourced on Github that contained a lot of the logic of our offering, but we still had a closed source server that handled both the interface to the LLM and the vector database that serves context, without an open source, locally runnable alternative. No longer!
The Challenges of AI-Generated SQL
Everyone we’ve talked to loves the idea of AI generated SQL - as data continues to grow in complexity and volume, the demand for simplified querying is at an all-time high. Traditional SQL query generation is often time-consuming and requires specialized skills that most people just don’t have. AI-generated SQL can be a game-changer, but it needs the following:
- High accuracy rates. High accuracy rates ensure that AI-generated SQL delivers precise and reliable results and builds trust with technical and business users alike.
- Easily trainable. The system must be adaptable to custom training on an enterprise's unique data schema, allowing for a tailored fit to specific internal data structures.
- Secure. Ensuring security is paramount, as AI-generated SQL must protect sensitive data and restrict sending data outside a company’s ecosystem unless required.
We are well on our way to enabling each of the three above (for example, see our white paper on improving accuracy rates). We believe that open sourcing Vanna will help with all of the above.
Why we are open sourcing Vanna
We're making Vanna open source for several key reasons:
- Security: A local deployment option ensures all data and queries stay within your ecosystem, which is especially useful in industries that are regulated or more risk averse (like finance and healthcare).
- Customization: Going open source allows users to swap out storage and lower-level models (LLMs) to suit their unique requirements.
- Establish a standard: The data ecosystem will benefit from a standard open source library that can subsequently be tailored to various needs.
Deploying Vanna Locally
Deploying Vanna locally is a straightforward process.
You'll need Python 3.x and pip installed on your machine. The following code will install Vanna, connect it to a locally defined LLM call, train a dedicated Vanna model, and ask a question in plain English:
%pip install 'vanna[chromadb,snowflake,openai]'
from vanna.local import LocalContext_OpenAI
vn = LocalContext_OpenAI({"api_key": "sk-..."})
vn.train(sql="...")
vn.ask()
Full details on how to use Vanna’s open source and locally deployable option are documented here .
Swapping out components to suit your needs: A Brief Overview
Vanna is designed to be extensible and flexible. Our open source and locally runnable version of Vanna offers the ability to swap out four different components.
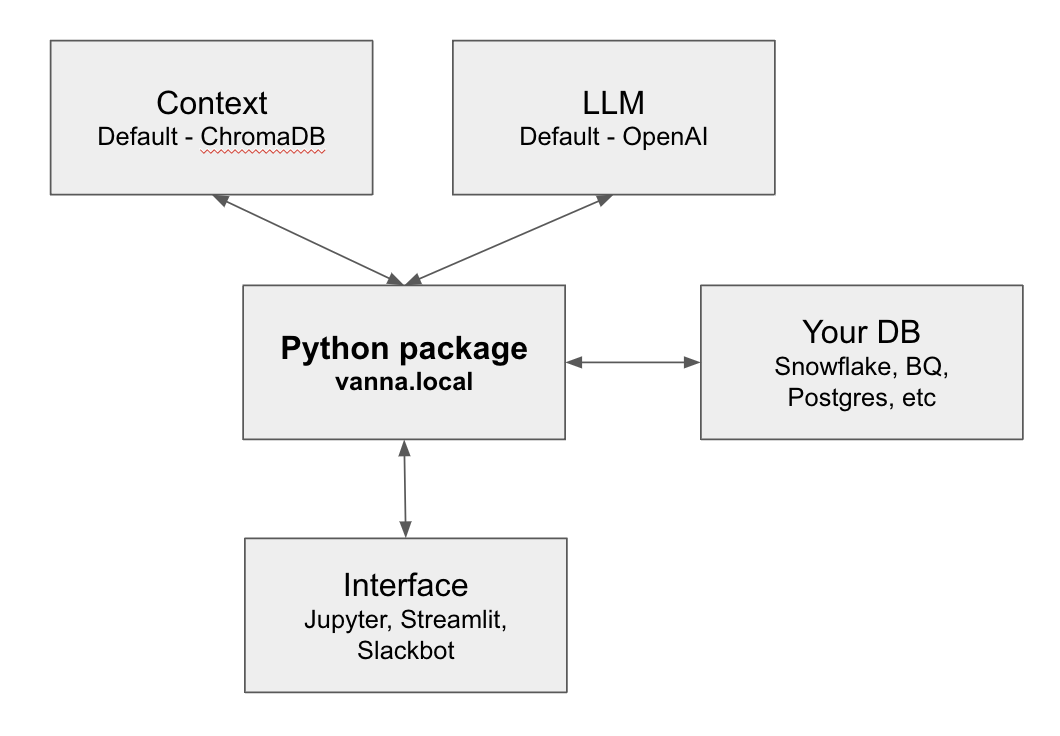
- Storage: Vanna's modular architecture supports multiple storage backends. You can specify your preferred storage. ChromaDB comes as the default, but you can use Pinecone, Postgres with the pgvector extension, or any other vector database.
- LLM: Many users may want to experiment with different LLMs. We have a white paper where we compare the performance of GPT 4, GPT 3.5, and Bard. You can extend this list and even fine tune your own LLM.
- Database: Your database connection, schema, and all data stay 100% local. You can configure Vanna to connect to any database, but we have built in connectivity and tutorials for Snowflake , BigQuery , and Postgres .
- Interface: While most users start out using Vanna via a Jupyter Notebook , you can also use it in a locally runnable Streamlit app or host your own Slackbot . All three options can be configured to be 100% local, without interacting at all with Vanna’s servers.
Although this is not a comprehensive guide, detailed documentation is available here to help you with these customizations.
Local vs. Hosted Version
Which one is right for you? In most circumstances, the hosted version is still the better option - it’s quicker to get started, is more performant and powerful, and has less management overhead. However, in certain circumstances - where running everything locally is key for regulatory reasons, or where you need specific and unsupported storage / LLM integrations, using and modifying the open source version is the preferred option. Here's a quick comparison:
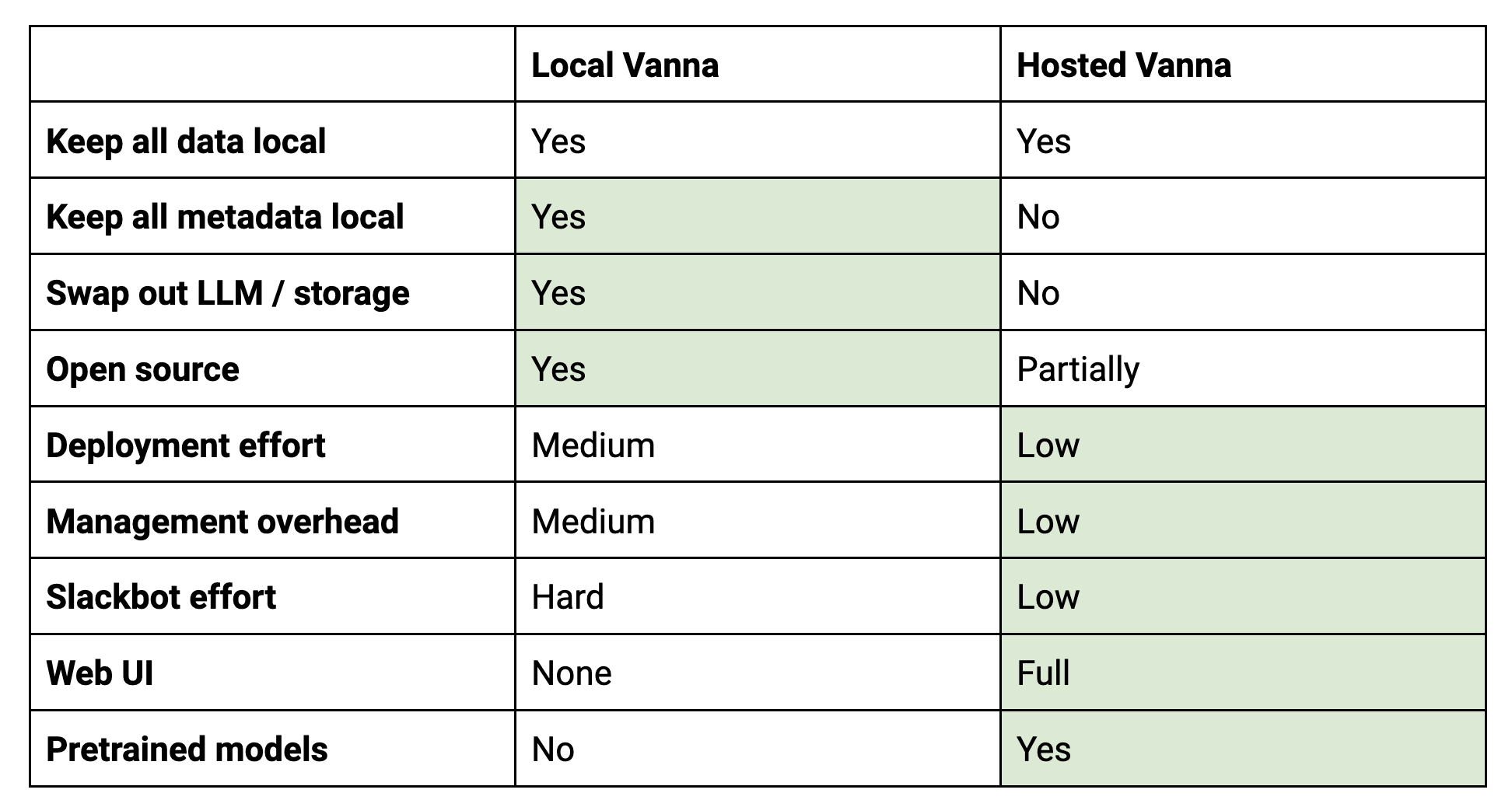
In short, the local version is better if you need really deep customization or are in a regulated industry and have resources available for DevOps. The hosted version is better if you prioritize additional functionality and ease of use.
Contributing to Vanna’s Open Source Version
We welcome contributors to Vanna’s open-source project via Github . Whether you're a developer, data scientist, or someone who's interested in AI and SQL, there are various ways to contribute:
- Code Contributions: Submit pull requests for new features or bug fixes.
- Documentation: Help improve our user guides and API documentation.
- Feature Suggestions: Share what features you’d like to see in future versions. We can't wait to see how the community takes Vanna to new heights. Your contributions will not only enrich the project but also pave the way for a more streamlined, efficient, and customizable AI-generated SQL ecosystem.
Wrapping Up
By open-sourcing Vanna, we aim to create a community around AI-generated SQL that thrives on collaboration, customization, and innovation. Join us in this exciting journey by trying out Vanna, contributing to its growth, and making data querying easier and more efficient for everyone.
For more details and to get started, visit our documentation .
Happy Querying (errr Asking)!
