AI SQL Accuracy: Testing different LLMs + context strategies to maximize SQL generation accuracy
2023-08-17
TLDR
The promise of having an autonomous AI agent that can answer business users’ plain English questions is an attractive but thus far elusive proposition. Many have tried, with limited success, to get ChatGPT to write. The failure is primarily due of a lack of the LLM's knowledge of the particular dataset it’s being asked to query.
In this paper, we show that context is everything, and with the right context, we can get from ~3% accuracy to ~80% accuracy . We go through three different context strategies, and showcase one that is the clear winner - where we combine schema definitions, documentation, and prior SQL queries with a relevance search.
We also compare a few different LLMs - including Google Bison, GPT 3.5, GPT 4, and a brief attempt with Llama 2. While GPT 4 takes the crown of the best overall LLM for generating SQL , Google’s Bison is roughly equivalent when enough context is provided.
Finally, we show how you can use the methods demonstrated here to generate SQL for your database.
Here's a summary of our key findings -
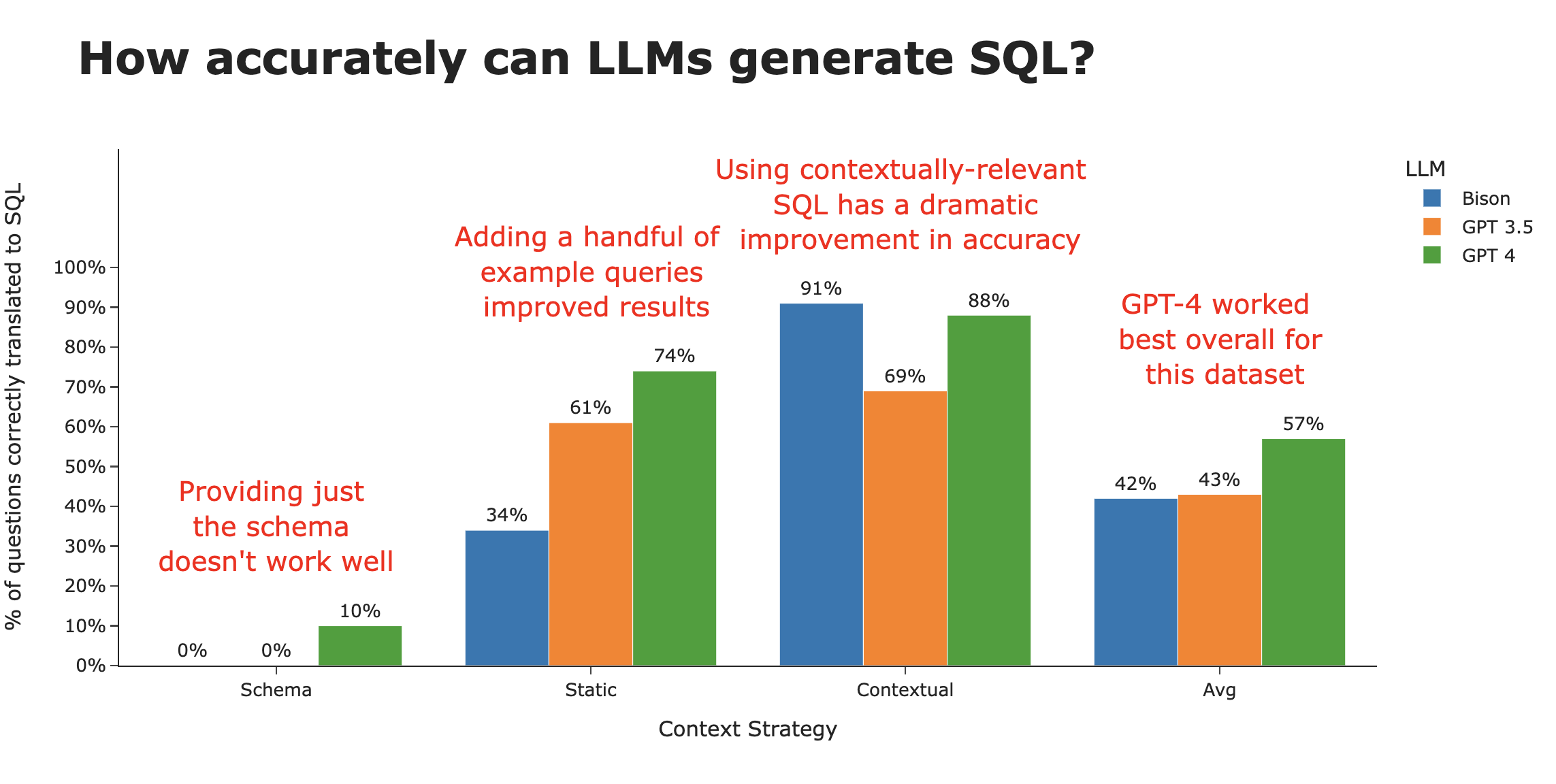
Table of Contents
- Why use AI to generate SQL?
- Setting up architecture of the test
- Setting up the test levers
- Using ChatGPT to generate SQL
- Using schema only
- Using SQL examples
- Using contextually relevant examples
- Analyzing the results
- Next steps to getting accuracy even higher
- Use AI to write SQL for your dataset
Why use AI to generate SQL?
Many organizations have now adopted some sort of data warehouse or data lake - a repository of a lot of the organization’s critical data that is queryable for analytical purposes. This ocean of data is brimming with potential insights, but only a small fraction of people in an enterprise have the two skills required to harness the data —
- A solid comprehension of advanced SQL , and
- A comprehensive knowledge of the organization’s unique data structure & schema
The number of people with both of the above is not only vanishingly small, but likely not the same people that have the majority of the questions.
So what actually happens inside organizations? Business users, like product managers, sales managers, and executives, have data questions that will inform business decisions and strategy. They’ll first check dashboards, but most questions are ad hoc and specific, and the answers aren’t available, so they’ll ask a data analyst or engineer - whomever possesses the combination of skills above. These people are busy, and take a while to get to the request, and as soon as they get an answer, the business user has follow up questions.
This process is painful for both the business user (long lead times to get answers) and the analyst (distracts from their main projects), and leads to many potential insights being lost.

Enter generative AI! LLMs potentially give the opportunity to business users to query the database in plain English (with the LLMs doing the SQL translation), and we have heard from dozens of companies that this would be a game changer for their data teams and even their businesses.
The key challenge is generating accurate SQL for complex and messy databases . Plenty of people we’ve spoken with have tried to use ChatGPT to write SQL with limited success and a lot of pain. Many have given up and reverted back to the old fashioned way of manually writing SQL. At best, ChatGPT is a sometimes useful co-pilot for analysts to get syntax right.
But there’s hope! We’ve spent the last few months immersed in this problem, trying various models, techniques and approaches to improve the accuracy of SQL generated by LLMs. In this paper, we show the performance of various LLMs and how the strategy of providing contextually relevant correct SQL to the LLM can allow the LLM to achieve extremely high accuracy .
Setting up architecture of the test
First, we needed to define the architecture of the test. A rough outline is below, in a five step process, with pseudo code below -
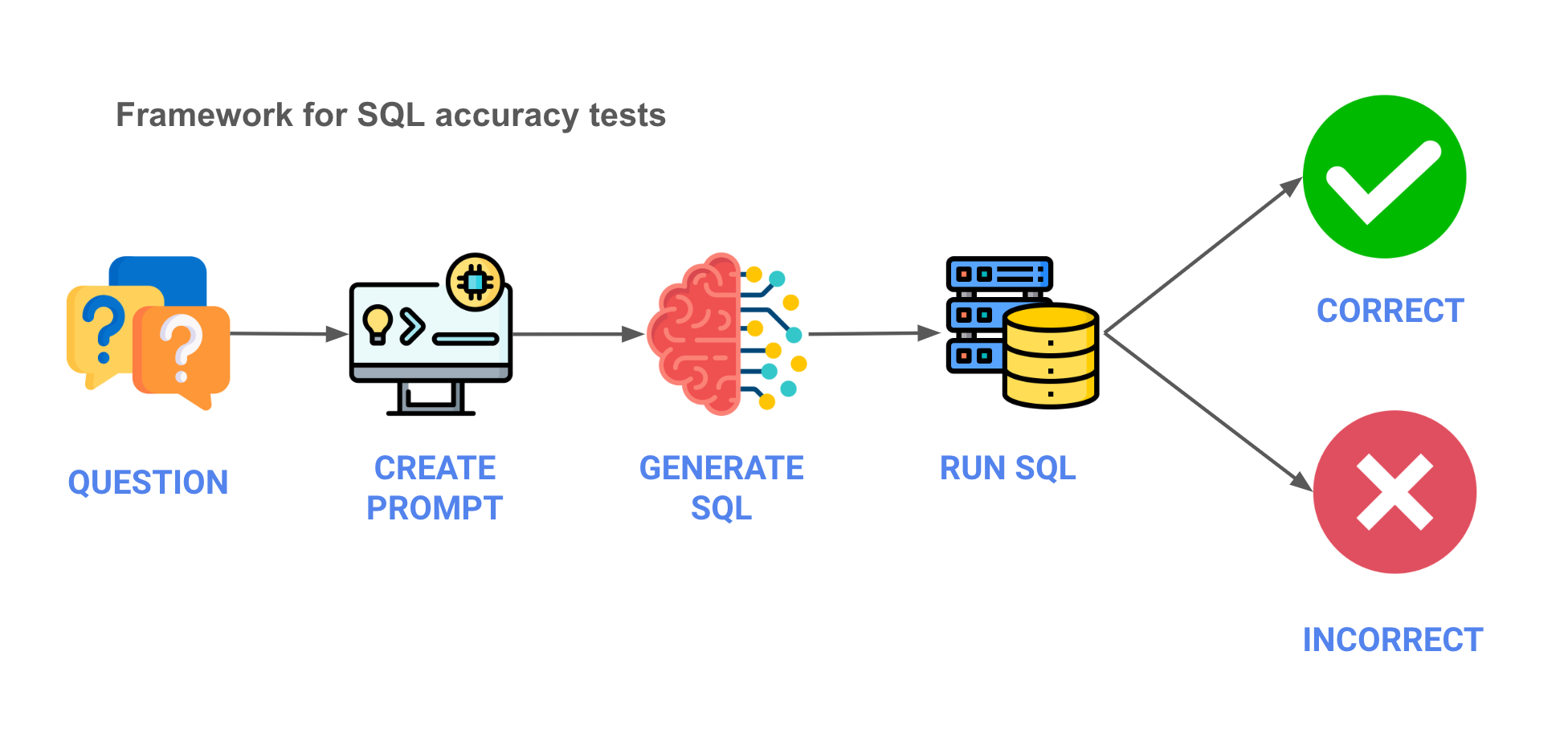
- Question - We start with the business question.
question = "how many clients are there in germany"
- Prompt - We create the prompt to send to the LLM.
prompt = f"""
Write a SQL statement for the following question:
{question}
"""
- Generate SQL - Using an API, we’ll send the prompt to the LLM and get back generated SQL.
sql = llm.api(api_key=api_key, prompt=prompt, parameters=parameters)
- Run SQL - We'll run the SQL against the database.
df = db.conn.execute(sql)
- Validate results - Finally, we’ll validate that the results are in line with what we expect. There are some shades of grey when it comes to the results so we did a manual evaluation of the results. You can see those results here
Setting up the test levers
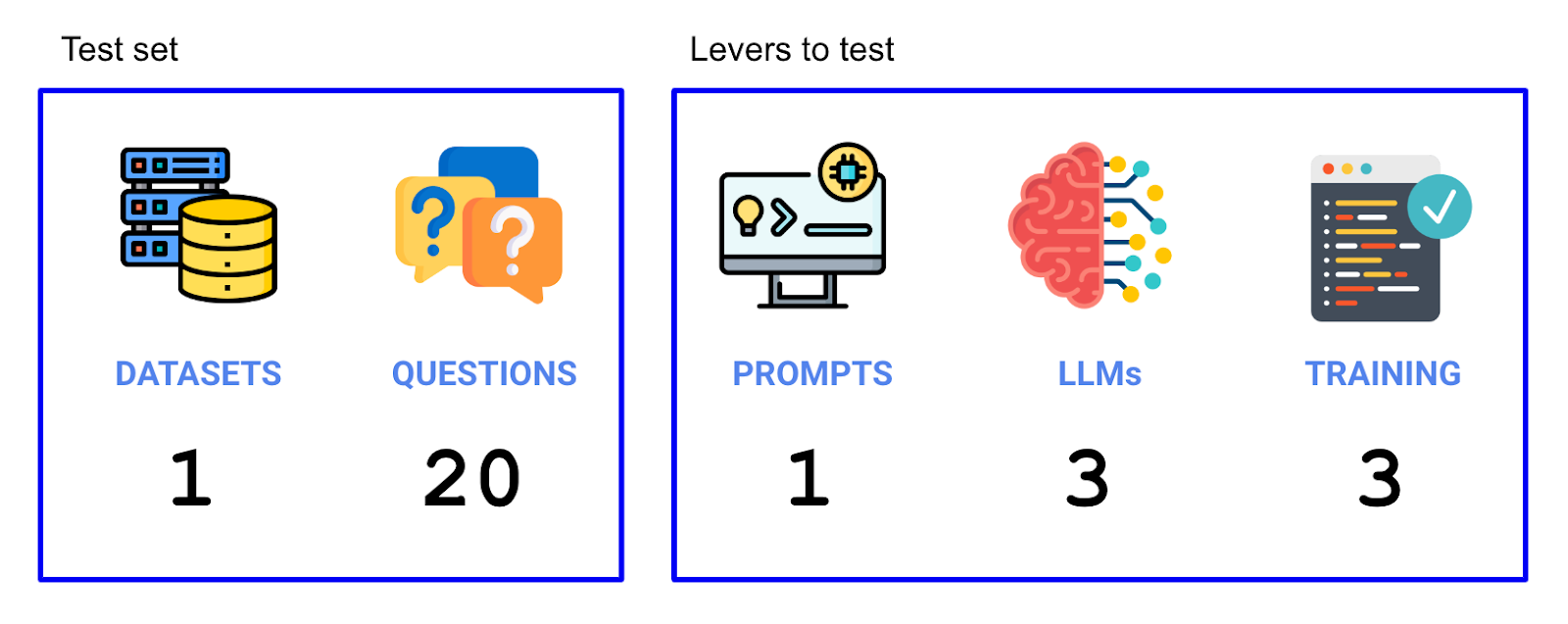
Now that we have our experiment set up, we’ll need to figure out what levers would impact accuracy, and what our test set would be. We tried two levers (the LLMs and the training data used), and we ran on 20 questions that made up our test set. So we ran a total of 3 LLMs x 3 context strategies x 20 questions = 180 individual trials in this experiment.
Choosing a dataset
First, we need to choose an appropriate dataset to try. We had a few guiding principles -
- Representative . Datasets in enterprises are often complex and this complexity isn’t captured in many demo / sample datasets. We want to use a complicated database that has real-word use cases that contains real-world data.
- Accessible . We also wanted that dataset to be publicly available.
- Understandable . The dataset should be somewhat understandable to a wide audience - anything too niche or technical would be difficult to decipher.
- Maintained . We’d prefer a dataset that’s maintained and updated properly, in reflection of a real database.
A dataset that we found that met the criteria above was the Cybersyn SEC filings dataset, which is available for free on the Snowflake marketplace:
https://docs.cybersyn.com/our-data-products/economic-and-financial/sec-filings
Choosing the questions
Next, we need to choose the questions . Here are some sample questions (see them all in this file ) -
- How many companies are there in the dataset?
- What annual measures are available from the 'ALPHABET INC.' Income Statement?
- What are the quarterly 'Automotive sales' and 'Automotive leasing' for Tesla?
- How many Chipotle restaurants are there currently?
Now that we have the dataset + questions, we’ll need to come up with the levers.
Choosing the prompt
For the prompt , for this run, we are going to hold the prompt constant, though we’ll do a follow up which varies the prompt.
Choosing the LLMs (Foundational models)
For the LLMs to test, we’ll try the following -
- Bison (Google) - Bison is the version of PaLM 2 that’s available via GCP APIs.
- GPT 3.5 Turbo (OpenAI) - GPT 3.5 until recently was the flagship OpenAI model despite 4 being available because of latency and cost benefits, and not a huge accuracy difference (well - we’ll put that to the test) especially for basic tasks.
- GPT 4 (OpenAI) - The more advanced but less performant OpenAI model. GPT 4 is multi-modal, though we won’t be using that functionality.
- Llama 2 (Meta) - We really wanted to include an open source model - and the leading one is Meta’s Llama 2. But our setup through Replicate quickly conked out, and we weren’t able to fix it in time for publishing this. In our early runs, when it did work, we found performance to be mediocre at best.
Choosing the context
Finally, we’ll have three types of context . Context refers to what we send to the LLM that helps give the LLM context on our specific dataset.
- Schema only . We put the schema (using DDL) in the context window.
- Static examples . We put static example SQL queries in the context windows.
- Contextually relevant examples . Finally, we put the most relevant context (SQL / DDL / documentation) into the context window, finding it via a vector search based on embeddings.
Using ChatGPT to generate SQL
This section is a bit unfair to ChatGPT, but it’s a helpful place to get started. Let’s just take a question and ask ChatGPT to generate the SQL -
Prompt
Write Snowflake SQL to answer the following question -
What are the quarterly revenues by business segment for Alphabet?
Return SQL only
Response
Certainly, here's the SQL query:
SELECT
EXTRACT(QUARTER FROM date_column) AS quarter,
business_segment,
SUM(revenue) AS quarterly_revenue
FROM
revenue_table
WHERE
company_name = 'Alphabet'
GROUP BY
quarter,
business_segment
ORDER BY
quarter,
business_segment;
-- Replace date_column, business_segment, revenue, revenue_table, and adjust any other identifiers to match your specific database schema.
Inevitably, when we try to run this, we hit an error, because it made up the table name since we didn't provide it -

Of course, we are being unfair to the LLMs - as magical as they are, they cannot (unfortunately? luckily?) possibly know what’s in our database - yet. So let’s hop into the tests where we give more context.
Using schema only
First, we take the schema of the dataset and put it into the context window. This is usually what we've seen people do with ChatGPT or in tutorials.
An example prompt may look like this (in reality we used the information schema because of how Snowflake shares work but this shows the principle) -
The user provides a question and you provide SQL. You will only respond with SQL code and not with any explanations.
Respond with only SQL code. Do not answer with any explanations -- just the code.
You may use the following DDL statements as a reference for what tables might be available.
CREATE TABLE Table1...
CREATE TABLE Table2...
CREATE TABLE Table3...
The results were, in a word, terrible. Of the 60 attempts (20 questions x 3 models), only two questions were answered correctly (both by GPT 4), for an abysmal accuracy rate of 3% . Here are the two questions that GPT 4 managed to get right -
- What are the top 10 measure descriptions by frequency?
- What are the distinct statements in the report attributes?
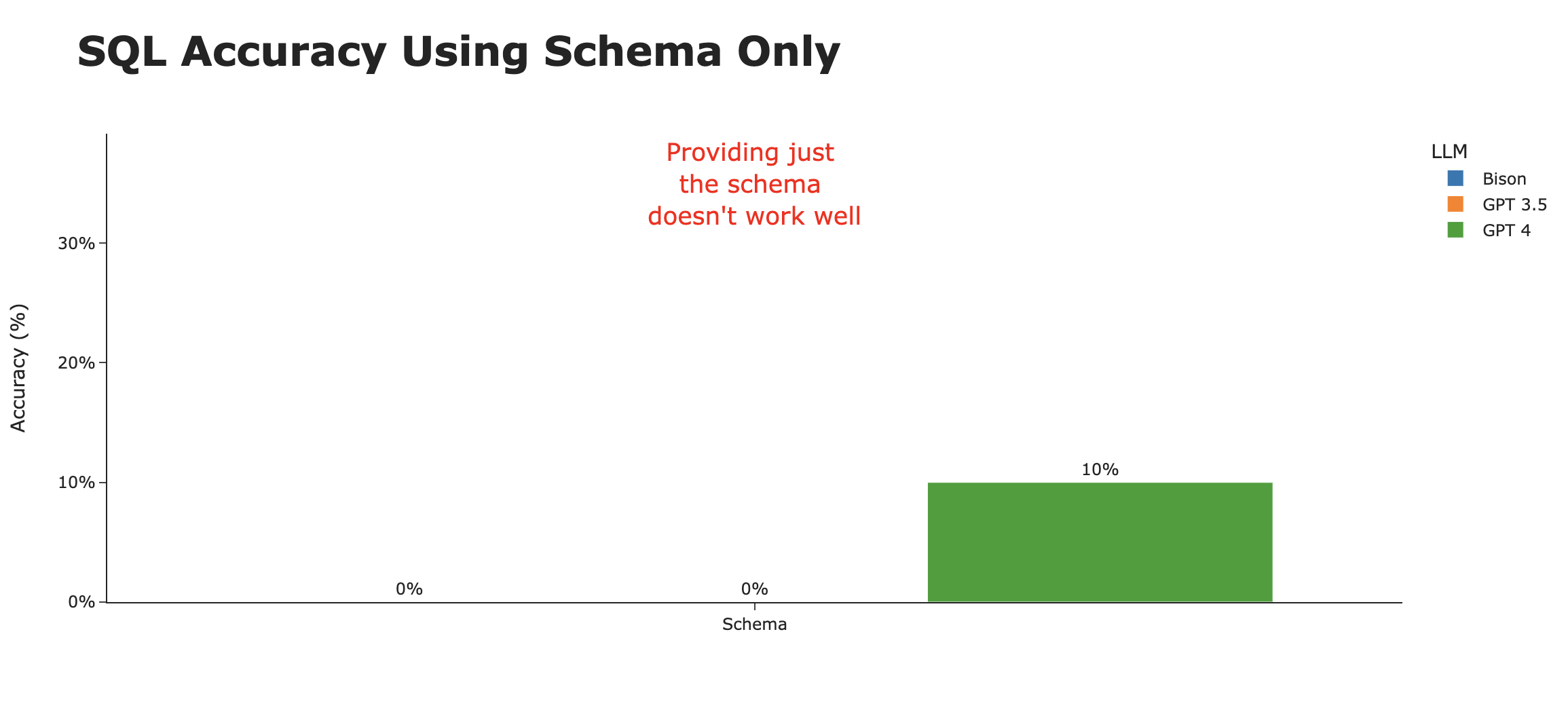
It’s evident that by just using the schema, we don’t get close to meeting the bar of a helpful AI SQL agent, though it may be somewhat useful in being an analyst copilot.
Using SQL examples
If we put ourselves in the shoes of a human who’s exposed to this dataset for the first time, in addition to the table definitions, they’d first look at the example queries to see how to query the database correctly.
These queries can give additional context not available in the schema - for example, which columns to use, how tables join together, and other intricacies of querying that particular dataset.
Cybersyn, as with other data providers on the Snowflake marketplace, provides a few (in this case 3) example queries in their documentation. Let’s include these in the context window.
By providing just those 3 example queries, we see substantial improvements to the correctness of the SQL generated. However, this accuracy greatly varies by the underlying LLM. It seems that GPT-4 is the most able to generalize the example queries in a way that generates the most accurate SQL.
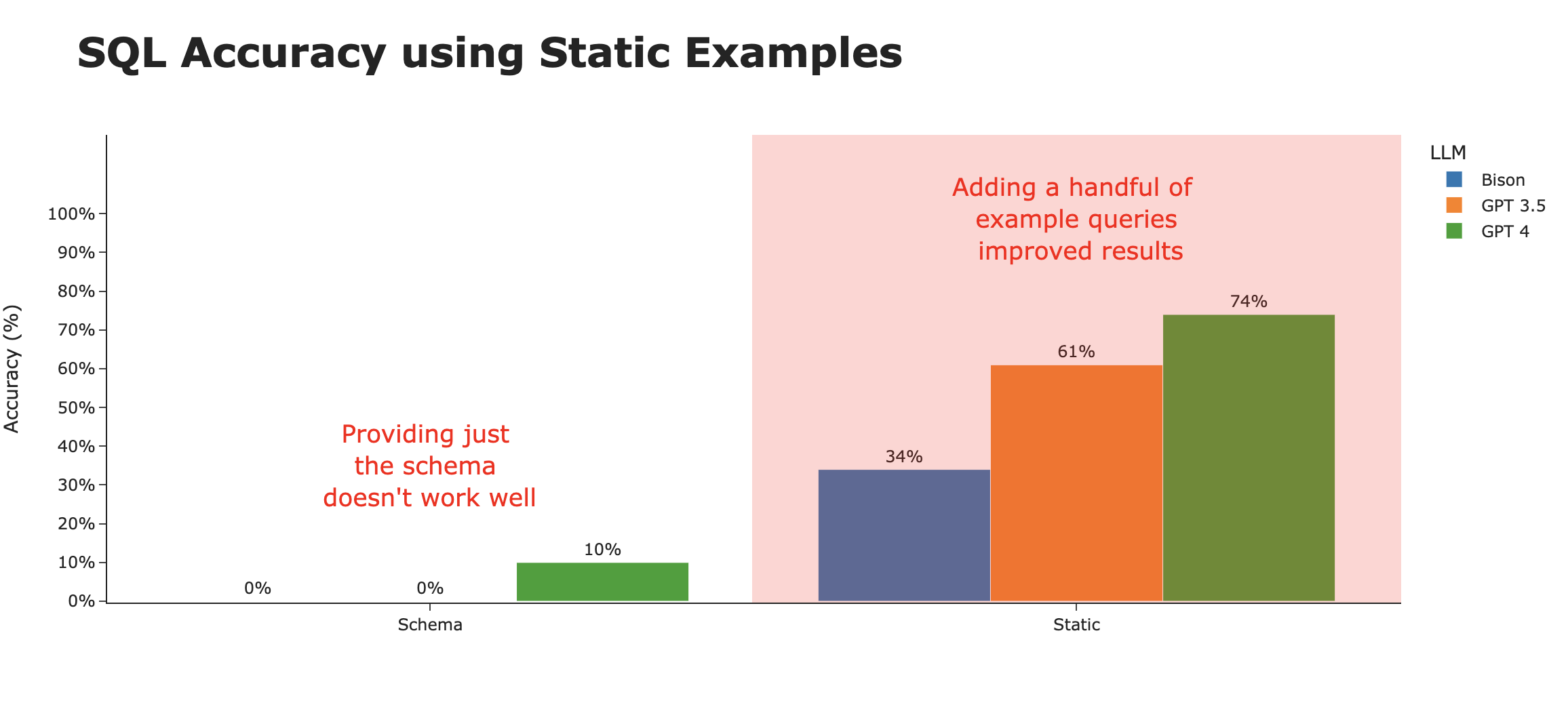
Using contextually relevant examples
Enterprise data warehouses often contain 100s (or even 1000s) of tables, and an order of magnitude more queries that cover all the use cases within their organizations. Given the limited size of the context windows of modern LLMs, we can’t just shove all the prior queries and schema definitions into the prompt.
Our final approach to context is a more sophisticated ML approach - load embeddings of prior queries and the table schemas into a vector database, and only choose the most relevant queries / tables to the question asked. Here's a diagram of what we are doing - note the contextual relevance search in the red box -
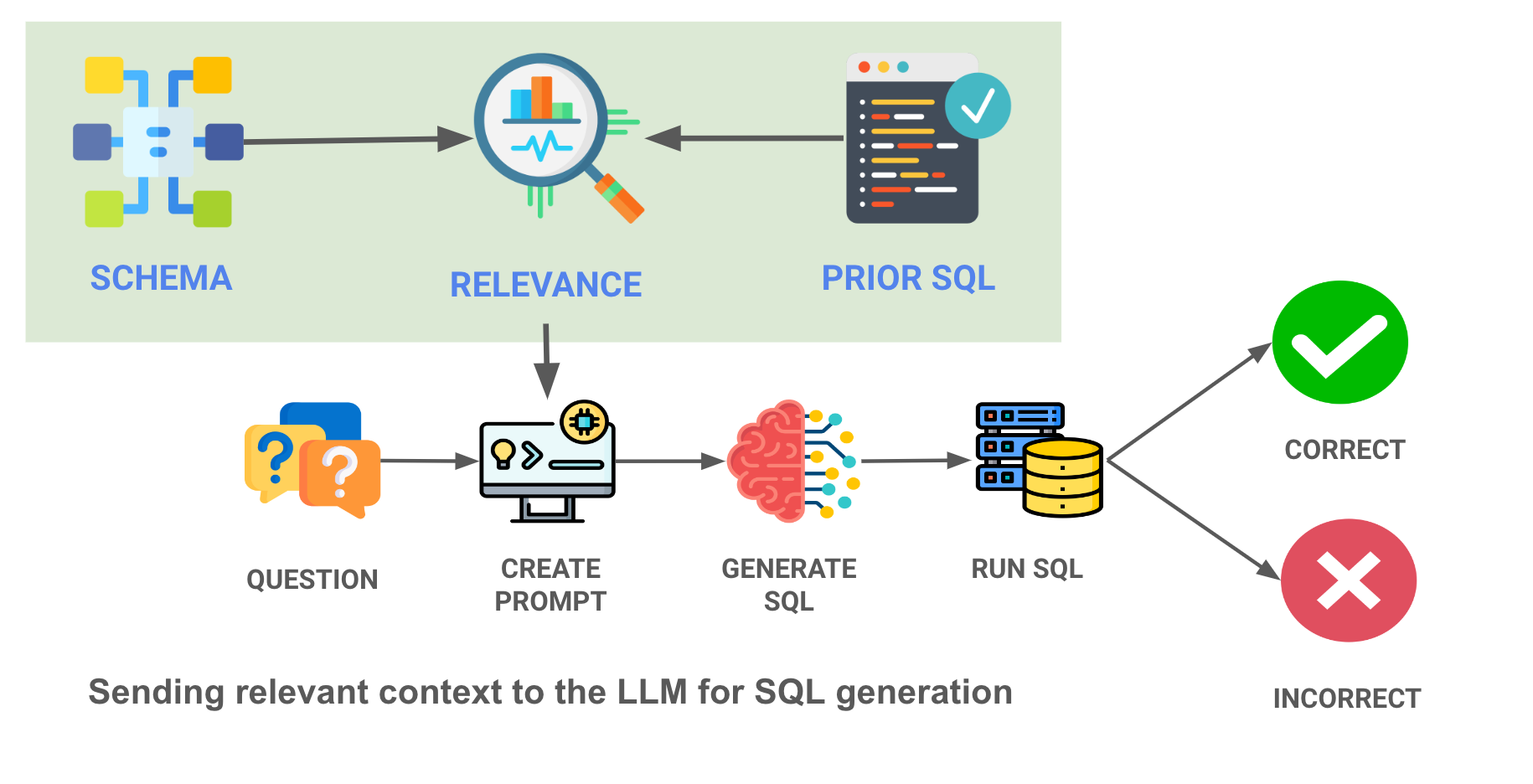
By surfacing the most relevant examples of those SQL queries to the LLM, we can drastically improve performance of even the less capable LLMs. Here, we give the LLM the 10 most relevant SQL query examples for the question (from a list of 30 examples stored), and accuracy rates skyrocket.

We can improve performance even more by maintaining a history of SQL statements that were executable and correctly answer actual questions that users have had.
Analyzing the results
It’s clear that the biggest difference is not in the type of LLM, but rather in the strategy employed to give the appropriate context to the LLM (eg the “training data” used).

When looking at SQL accuracy by context strategy, it’s clear that this is what makes the difference. We go from ~3% accurate using just the schema, to ~80% accurate when intelligently using contextual examples.
There are still interesting trends with the LLMs themselves. While Bison starts out at the bottom of the heap in both the Schema and Static context strategies, it rockets to the top with a full Contextual strategy. Averaged across the three strategies, GPT 4 takes the crown as the best LLM for SQL generation .
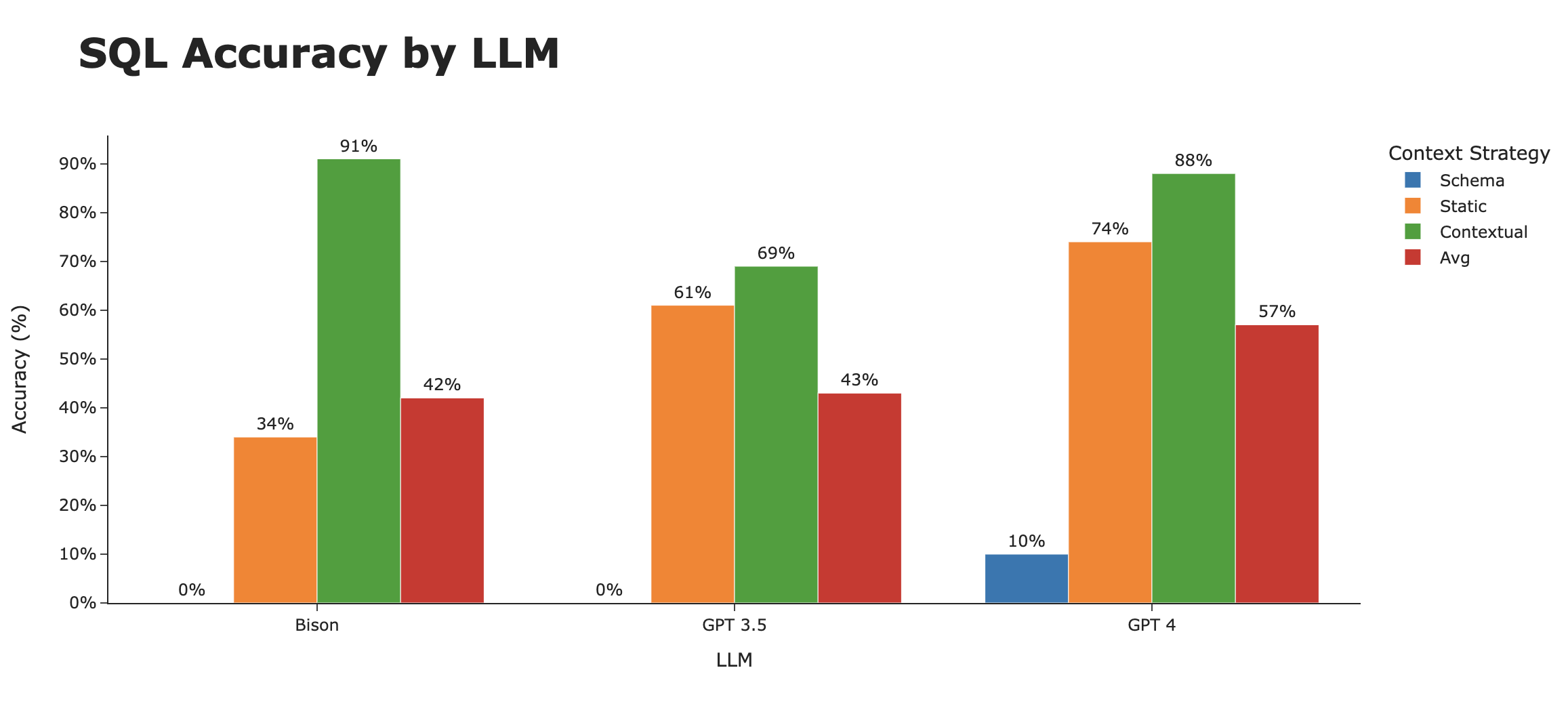
Next steps to getting accuracy even higher
We'll soon do a follow up on this analysis to get even deeper into accurate SQL generation. Some next steps are -
- Use other datasets : We'd love to try this on other, real world, enterprise datasets. What happens when you get to 100 tables? 1000 tables?
- Add more training data : While 30 queries is great, what happens when you 10x, 100x that number?
- Try more databases : This test was run on a Snowflake database, but we've also gotten this working on BigQuery, Postgres, Redshift, and SQL Server.
- Experiment with more foundational models: We are close to being able to use Llama 2, and we'd love to try other LLMs.
We have some anecdotal evidence for the above but we'll be expanding and refining our tests to include more of these items.
Use AI to write SQL for your dataset
While the SEC data is a good start, you must be wondering whether this could be relevant for your data and your organization. We’re building a Python package that can generate SQL for your database as well as additional functionality like being able to generate Plotly code for the charts, follow-up questions, and various other functions.
Here's an overview of how it works
import vanna as vn
- Train Using Schema
vn.train(ddl="CREATE TABLE ...")
- Train Using Documentation
vn.train(documentation="...")
- Train Using SQL Examples
vn.train(sql="SELECT ...")
- Generating SQL
The easiest ways to use Vanna out of the box are
vn.ask(question="What are the ...")
which will return the SQL, table, and chart as you can see in this
example notebook
.
vn.ask
is a wrapper around
vn.generate_sql
,
vn.run_sql
,
vn.generate_plotly_code
,
vn.get_plotly_figure
, and
vn.generate_followup_questions
. This will use optimized context to generate SQL for your question where Vanna will call the LLM for you.
Alternately, you can use
vn.get_related_training_data(question="What are the ...")
as shown in this
notebook
which will retrieve the most relevant context that you can use to construct your own prompt to send to any LLM.
This notebook shows an example of how the "Static" context strategy was used to train Vanna on the Cybersyn SEC dataset.
A note on nomenclature
- Foundational Model : This is the underlying LLM
- Context Model (aka Vanna Model) : This is a layer that sits on top of the LLM and provides context to the LLM
- Training : Generally when we refer to "training" we're talking about training the context model.
Contact Us
Ping us on Slack , Discord , or set up a 1:1 call if you have any issues.
